

Le RAID
Le RAID ( initialement Redundant Array of Inexpensive Disks, puis Redundant Array of Independent Disks, traduisez "Ensemble redondant de disques bon marché ou indépendants") est une technique qui consiste à utiliser plusieurs disques durs simultanément en les faisant apparaître comme un seul lecteur . Le but est d'accroître la vitesse des accès en traitant plus de données en parallèle et/ou de sécuriser les données des disques par l'ajout d'informations redondantes.
Le concept du RAID fut lancé en 1987 à l'université de Berkeley par un article qui décrivait six manières différentes de regrouper des disques. Ces configurations ont été numérotées de 0 à 5. On les désigne par des "niveaux RAID" ou "RAID levels" : RAID 0 à RAID 5.
D'autres architectures RAID sont apparues par la suite ( 6 et 7) et des constructeurs proposent des RAID à plusieurs niveaux : 0+1, 1+0 ou 5+0 par exemple.
La gestion d'un RAID se fait de manière logicielle ou matérielle. La solution logicielle dépend du système d'exploitation et utilise les ressources mémoire et CPU du système, il s'agit d'un driver qui combine plusieurs disques en un seul lecteur logique. La solution matérielle est indépendante du système d'exploitation. Elle recourt à un circuit contrôleur RAID actuellement de plus en plus souvent intégré à la carte mère. Ce circuit contrôle les commandes envoyées à la grappe de disque, ce qui allège le travail du processeur.
RAID 0
Cette technique, le "striping" implique un minimum de
deux disques. En fait, au lieu de parler de RAID on devrait ici parler de
"AID" puisque ici on n'ajoute pas de redondance pour être plus
fiable. Les données sont découpées en bandes (en anglais : strips ) constituées
d'un nombre fixe de secteurs. Ces bandes sont ensuite réparties entre les
disques de manière à partager le travail lors d'accès à des données volumineuses.
Une requête d'entrée sortie qui concerne plusieurs bandes consécutives sollicite
donc plusieurs disques simultanément. Chacun peut répondre plus vite puisqu'il
aura moins à faire.
Cette technique augmente la vitesse de leurs transferts mais n'assure pas
la sécurité des données. Si un disque tombe en panne, la totalité des données
est perdue.
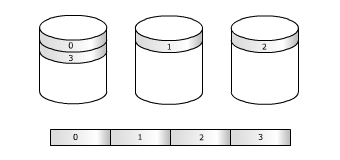
Ex : Enregistrement de quatre bandes
sur une grappe de trois disques
RAID 1
Le principe du RAID 1, le mirroring consiste à dupliquer les données sur deux disques (ou plus mais toujours un nombre pair), de ce fait, si un disque tombe en panne, l'autre disque contenant la copie de ses données prend alors le relais. Ce remplacement peut en plus se faire sans éteindre l'ordinateur, option avantageuse pour les serveurs qui ne peuvent pas être arrêtés. On parle dans ce cas de tolérance de pannes puisque ce système assure la continuité du service.
Les performances en vitesse sont fort semblables à celle d'un disque unique. Lors des requêtes d'écriture, c'est du disque le plus lent que va dépendre la durée de l'opération. Pour les lectures, il est possible de répartir les requêtes de sorte à partager le travail et à améliorer ainsi la bande passante.
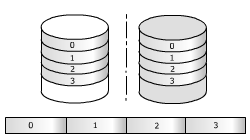
Ex. : Enregistrement de quatre bandes
sur deux disques en miroir
RAID 10 et RAID 0+1
Certains constructeurs proposent ces systèmes RAID à deux niveaux qui combinent le RAID 1 et le RAID 0 pour assurer simultanément sécurité (RAID1) et vitesse (RAID 0).
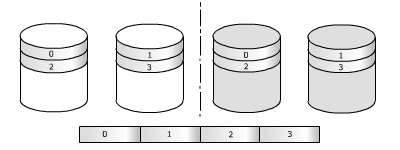
RAID 01 "mirror of stripes"
ou RAID 10 "stripe of mirrors"
RAID 2
Le RAID 2 est une configuration imaginée en 1988, en même temps que les autres configurations RAID mais qui s'est révélée inappropriée après coup. Elle n'est jamais utilisée.
Au lieu de couper les données en bandes d'un ou plusieurs secteurs on les subdivise en mots de quelques bits ou octets qu'on disperse sur les disques en ajoutant des codes de contrôle et de correction d'erreur.
Imaginez par exemple quatre disques qui se partagent des mots de 4 bits. Les concepteurs du RAID 2 envisageaient de placer 3 disques supplémentaires afin d'y enregistrer 3 bits de contrôle calculés de sorte à pouvoir corriger une erreur qui viendrait se glisser dans l'un de ces 7 disques. ( Code de Hamming)
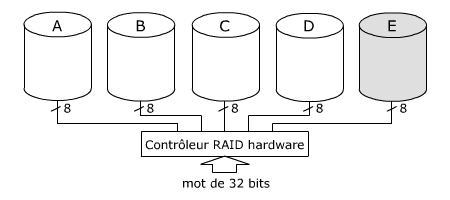
RAID 3
Le RAID 3 tout comme le RAID 2 égraine les données en mots au lieu de les
partager en bandes de un ou plusieurs secteurs. La méthode de contrôle et
correction consiste à utiliser un disque redondant en tant que disque de
parité. Les accès se font en parallèle.
Exemple : 5 disques pour stocker des données organisées en mots de 32 bits.
Les 32 bits sont partagés en 4 octets. Chaque octet est dirigé vers un disque
différent, un cinquième octet calculé à partir des quatre premiers est copié
sur le cinquième disque. Ce calcul, un OU exclusif ou ce qui revient au
même, la détermination d'un bit de parité, permet de retrouver n'importe
quel octet à partir des quatre autres. A la lecture, le contrôleur RAID
vérifie chaque combinaison des 5 octets avant de rendre les 32 bits initiaux.
La moindre défaillance d'un disque est vite détectée et corrigée.
Dans ce système les têtes de lecture/écriture des disques sont synchronisées en permanence. Ce système est à la fois rapide et tolérant aux pannes. Il est surtout efficace pour les gros volumes de données, les serveurs vidéo par exemple.
Si un des disques tombe en panne, les données peuvent être reconstituées à partir des disques restés intacts. Si par contre, plusieurs disques tombent en panne, il devient alors impossible de restituer les données.
RAID 4 ET 5
 RAID 4
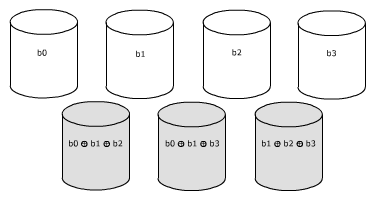
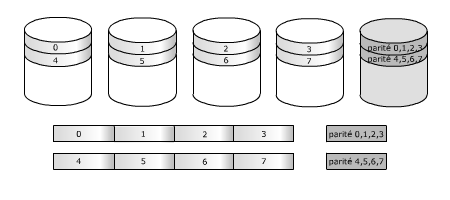
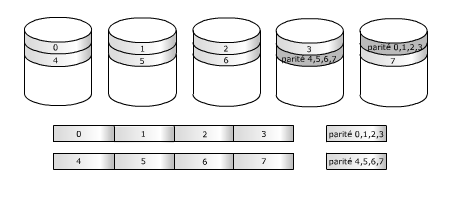
RAID 4Les RAID 4 et 5 ressemblent au RAID 3 mais sans forcer les disques à travailler en synchronisme car au lieu de subdiviser chaque mot en fragments envoyés simultanément vers chaque disque, il travaille comme le RAID 0 ou le RAID 1, avec des bandes. Dans le RAID 4, les n premiers disques reçoivent n bandes, le disque redondant reçoit un bloc de données calculé par un OU-exclusif à partir des n bandes précédentes. Le RAID 5 est une variante où la bande de parité occupe tour à tour chacun des disques.
 RAID 5
RAID 5
Quelques liens externes pour en savoir encore plus sur le sujet :
-
Le RAID : technologie Intel
Combinaison RAID disponibles sur les cartes mères selon le chipset (ICH) - RAID Tutorial présentation en anglais avec animations bien faites pour nous aider à comprendre.

